Fine-tuning AI models

What is Fine tuning a machine learning model?
Fine-tuning AI models involves taking a pre-existing model, like an open-source one, and enhancing its performance by training it on specific datasets. The base model acts as the foundation, possessing general knowledge and skills. To fine-tune it, you expose the model to new, more specialized data. This process allows the AI to learn patterns and nuances within this specific dataset, improving its ability to comprehend and generate content related to that information.
The success of fine-tuning depends on various factors, like the quality and size of the dataset, the relevance of the data to the task, and the tuning parameters. It’s crucial to balance the fine-tuning process, ensuring the AI gains specialized knowledge without losing its general understanding. Despite its potential, fine-tuning AI models requires careful handling. Inappropriate or biased data might lead to skewed outcomes, perpetuating existing prejudices or misconceptions within the model’s output.
How Fine-Tuning Works?
1. Begin with a pre-trained model trained on a large, diverse dataset.
2. Add a new task-specific layer on top of the pre-trained model. For instance, if it’s a sentiment analysis task, include a classification layer.
3. Keep the weights of the pre-trained layers frozen to retain the original knowledge.
4. Focus the training process solely on updating the weights of the newly added task-specific layer. This allows the model to adapt to the specific requirements of your new task.
5. Train the model using your specific dataset by feeding batches of data through the model and comparing the outputs with the actual labels.
6. After several training epochs dedicated to the task layer, consider unfreezing some pre-trained layer weights, enabling further adjustment on your dataset.
7. Continue training the model until the task layer and chosen pre-trained layers converge on the best-suited weights for your dataset.
8. The crux lies in preserving the majority of the original model’s weights during training, altering only a small subset to tailor the model to new data. This method transfers foundational knowledge while customizing the model for specific tasks.
Common use cases
• Setting the style, tone, format, or other qualitative aspects.
• Improving reliability at producing a desired output.
• Correcting failures to follow complex prompts.
• Handling many edge cases in specific ways.
• Performing a new skill or task that’s hard to articulate in a prompt.
OpenAI models open for fine-tuning
• Gpt-3.5
• Babbage-002
• Davinci-002
• Ada
• Curie
• Gpt-4-0613 (experimental — eligible users will be presented with an option to request access in the fine-tuning UI)
Which model to use will depend on your use case and how you value quality versus price and speed.
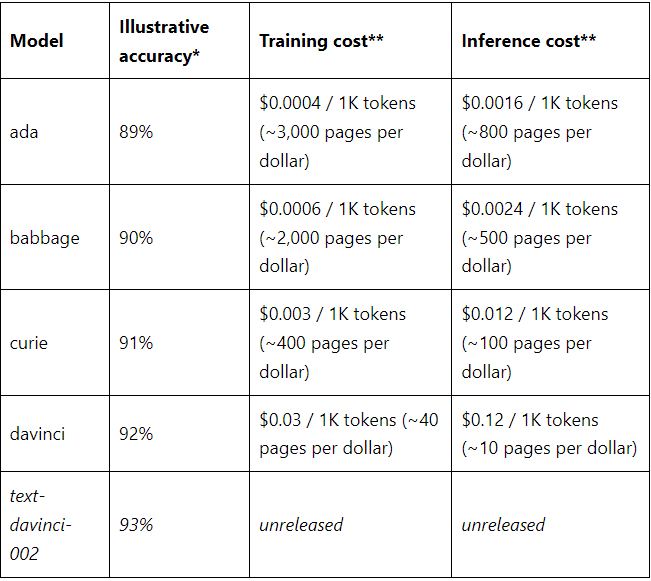
* Illustrative accuracy on the SNLI dataset, in which sentence pairs are classified as contradictions, implications, or neutral
**Pages per dollar figures assume ~800 tokens per page. OpenAI Pricing.
Stages of fine-tuning
• Prepare data.
• Upload the training data.
• Train a fresh, fine-tuned model.
• Employ the fine-tuned model.
Prepare data
Once you’ve determined that fine-tuning is necessary, the next step is preparing data for training. The preparation involves curating a diverse sample conversations resembling the discussions the model will encounter during actual usage in production. Each instance in the dataset should mirror the format used in our Chat Completions API (roles, content, names).
It’s essential to include examples that specifically address instances where the model fails to meet the desired behavior. The assistant’s responses provided within this dataset should exemplify the ideal replies you aim for the model to generate in those situations. These targeted examples play a crucial role in guiding the model toward the desired performance levels during the training phase.

Example format
Once dataset is compiled, it is recommended to check the data formatting before fine-tuning job creation. Use Python script to find potential errors, review token counts, and estimate the cost of a fine-tuning job.
The conversational chat format is required to fine-tune gpt-3.5-turbo. For babbage-002 and davinci-002, you can follow the prompt completion pair format used for legacy fine-tuning as shown below.

Promt Creation
When preparing prompts, it’s advisable to incorporate the instructions and prompts that previously demonstrated optimal performance for the model before fine-tuning. Including these in each training example can yield the most comprehensive and effective outcomes, especially if your dataset comprises relatively few instances (e.g., fewer than a hundred).
Should you consider shortening the repetitive instructions or prompts in each example to reduce expenses, bear in mind that the model will likely follow the patterns as if those instructions were explicitly present. Consequently, it might be challenging to compel the model to disregard these inherent instructions during inference.
It’s important to note that achieving satisfactory results might necessitate a larger number of training examples. This is because the model must learn primarily through demonstration without explicit guided instructions, potentially requiring more instances for effective learning and improved performance.
Example count recommendations
To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples with gpt-3.5-turbo but the right number varies greatly based on the exact use case.
We recommend starting with 50 well-crafted demonstrations and seeing if the model shows signs of improvement after fine-tuning. In some cases that may be sufficient, but even if the model is not yet production quality, clear improvements are a good sign that providing more data will continue to improve the model. No improvement suggests that you may need to rethink how to set up the task for the model or restructure the data before scaling beyond a limited example set.
Train and test splits
Upon acquiring the initial dataset, it’s advisable to partition it into training and test segments. When initiating a fine-tuning job with both training and test files, furnish statistics for both throughout the training process will be getting. These statistics serve as an initial indicator of the model’s improvement. Furthermore, creating a test set at an early stage proves beneficial in ensuring the ability to assess the model post-training by generating samples on the test set.
Token limits
Regarding token limits, each training example is constrained to 4096 tokens. Instances exceeding this limit will undergo truncation to the initial 4096 tokens during the training process. To ensure that your entire training example remains within context, it’s prudent to verify that the cumulative token count in the message contents does not surpass 4,000 tokens. This precaution ensures the comprehensive inclusion of the training example without exceeding the token limit.
Data formating
To effectively fine-tune a model, you’ll require a collection of training examples, each composed of a single input (“prompt”) and its corresponding output (“completion”). Every prompt should conclude with a consistent separator, delineating the end of the prompt and the initiation of the completion. A commonly effective separator is \n\n###\n\n, ensuring it doesn’t appear elsewhere within any prompt.
Each completion should commence with a whitespace due to tokenization, a process that generally requires most words to have a preceding whitespace. Additionally, each completion should conclude with a predefined stop sequence, signaling the model about the completion’s termination. The stop sequence could be \n, ###, or any other token absent from any completion. During inference, ensure the formatting of prompts mirrors the structure used when constructing the training dataset, including the identical separator. Likewise, specify the same stop sequence to accurately truncate the completion for appropriate model interpretation.
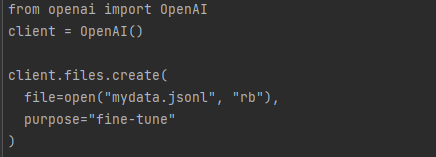
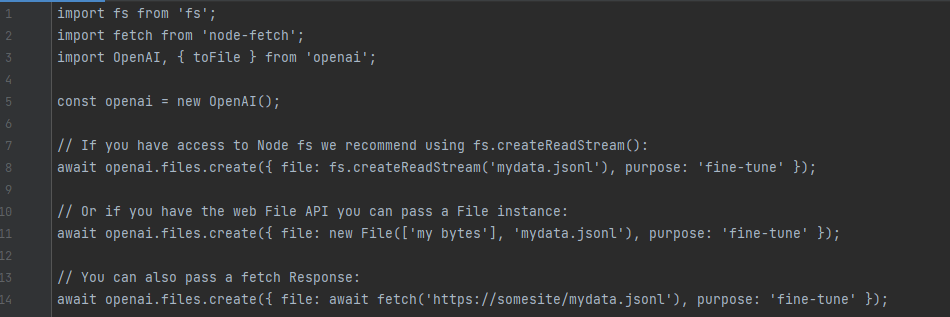
Upload training data
Once the data is validated, the file needs to be uploaded using the Files API to be used with a fine-tuning jobs:
Python
node.js

Curl
After file upload, it may take some time to process.
Fine-tune model creation
After getting the right amount and structure for dataset, and file uploding, the next stage is fine-tuning job creation.
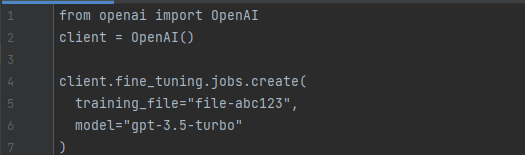
Start fine-tuning job using the OpenAI SDK:
Python
node.js
In this scenario, ‘model’ refers to the specific model you’re aiming to fine-tune, such as gpt-3.5-turbo, babbage-002, davinci-002, or an already fine-tuned model. The ‘training_file’ denotes the file ID obtained upon uploading the training file to the OpenAI API. You have the option to personalize your fine-tuned model’s name using the ‘suffix’ parameter.
For further fine-tuning customization, like specifying the ‘validation_file’ or adjusting hyperparameters, please consult the API specification dedicated to fine-tuning.
Once you’ve initiated a fine-tuning task, it might require some time to complete. The duration of training a model can range from minutes to hours, contingent on the model and dataset size. Upon completion of model training, the user who initiated the fine-tuning job will receive an email confirmation.
Beyond initiating a fine-tuning job, you also have the capability to list ongoing jobs, check the status of a specific job, or cancel a job as needed. This functionality grants flexibility and control over the fine-tuning process.
Fine-tune model use
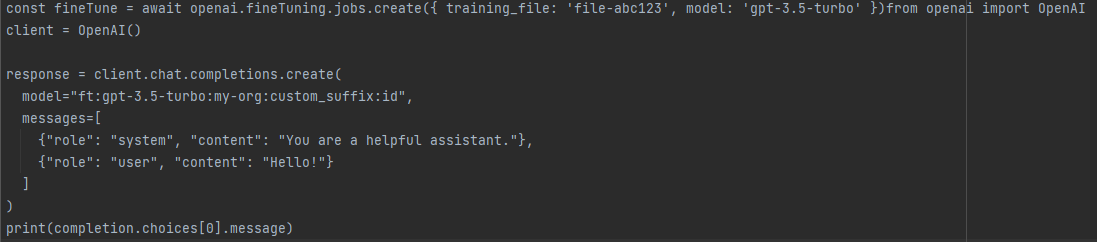
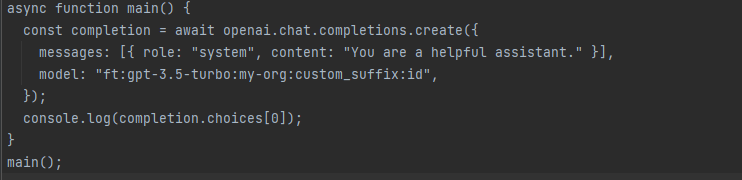
Upon successful completion of a job, the ‘fine_tuned_model’ field will contain the name of the model when accessing the job details. You can now specify this fine-tuned model as a parameter in the Chat Completions API (for gpt-3.5-turbo) or the legacy Completions API (for babbage-002 and davinci-002). Subsequently, you can make requests to this model using the Playground interface.
Once your job reaches completion, the model should promptly become available for inference purposes. However, in some instances, it might take a few minutes for the model to be fully ready to handle requests. If you encounter timeouts during requests to your model or encounter difficulties locating the model name, it’s likely that your model is still in the process of loading.
Python
node.js
You can start making requests by passing the model name.
Fine-tuning model examples
• Function calling
• Structured output
• Style and tone
Function calling
The chat completions API does support function calling. Nevertheless, incorporating an extensive list of functions within the completions API can consume a substantial number of prompt tokens. Occasionally, this might lead the model to hallucinate or produce invalid JSON output.
♦ Create assistants that answer questions by calling external APIs (e.g. like ChatGPT Plugins)
e.g. define functions like send_email (to: string, body: string), or get_current_weather (location: string, unit: ‘celsius’ | ‘fahrenheit’)
♦ Convert natural language into API calls
e.g. convert “Who are my top customers?” to get_customers (min_revenue: int, created_before: string, limit: int) and call your internal API
♦ Extract structured data from text
e.g. define a function called extract_data (name: string, birthday: string), or sql_query (query: string)
Employing function calling examples during model fine-tuning offers several advantages:
► Ensuring similarly formatted responses even in the absence of the full function definition.
► Enhancing the accuracy and consistency of outputs.
▲Within an API call, you have the capability to define functions, allowing the model to intelligently produce a JSON object containing arguments to execute one or multiple functions. Notably, the Chat Completions API does not directly execute the function; instead, it generates JSON output that you can subsequently utilize to invoke the function within your code. The latest models, such as gpt-3.5-turbo-1106 and gpt-4-1106-preview, have undergone training to identify situations where a function needs to be invoked based on the input provided. Moreover, these models are trained to provide JSON responses that align more closely with the function signature compared to their predecessors.
Format examples as illustrated, where each line contains a set of “messages” along with an optional set of “functions”.
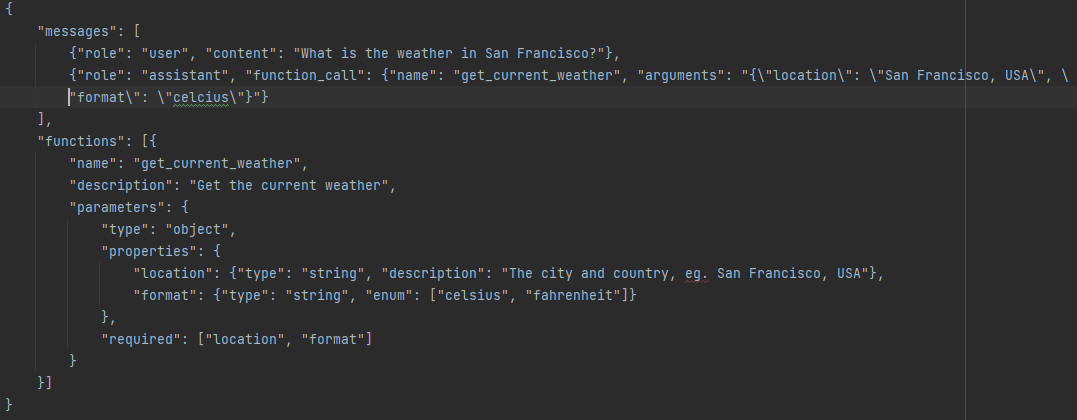
To actively engage in creating your own fine-tuned model, a minimum of 10 examples is required. Additionally, fine-tuning the model with function calling can be employed to tailor the model’s response to function outputs. To execute this, include a function response message alongside an assistant message interpreting that specific response:
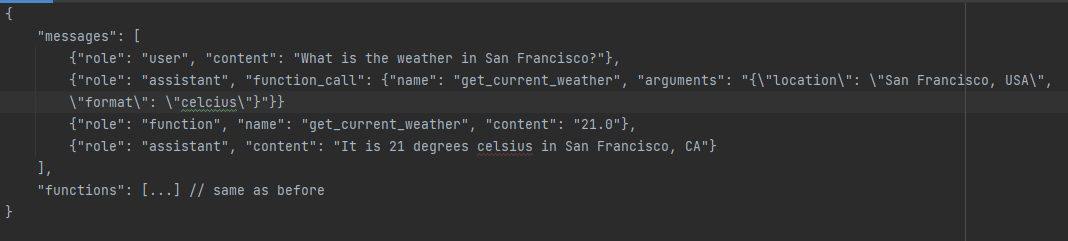
Structured output
This is use case which works really well with fine-tuning is getting the model to provide structured information, in the example below, sports headlines is presented.

To create your fine-tuned model, a minimum of 10 examples is essential. Following data acquisition aimed at potentially enhancing the model, the subsequent step involves verifying if the data complies with all the necessary formatting prerequisites.
Once the data is properly formatted and validated, the concluding stage in the training process involves initiating a job to generate the fine-tuned model. This can be accomplished through the OpenAI CLI or using one of the SDKs, demonstrated below:
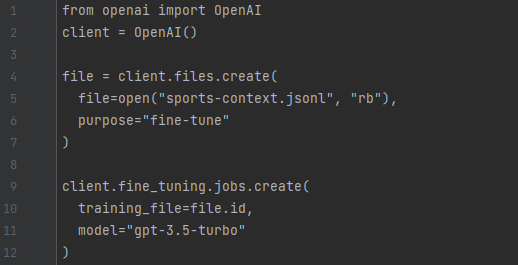
Once the training job is done, it is possible to use fine-tuned model and make a request that looks like the following:
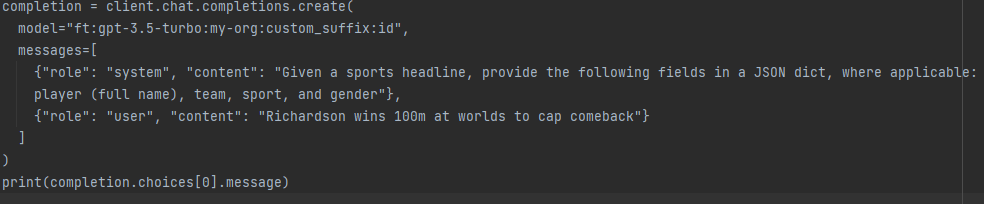
Based on the formatted training data, the response should look like that:

Style and tone
Let’s look at crafting a fine-tuned model capable of adhering to specific style and tone guidelines beyond the scope achievable through prompts alone. Generated sample collection of messages demonstrating what the model should emulate, focusing on misspelled words in this instance.

To actively participate in creating fine-tuned model, ensure there are minimum 10 examples available. Once you’ve acquired the data intended to potentially enhance the model, the subsequent step involves verifying if the data aligns with all the required formatting criteria. Now that the data has been formatted and validated, the final stage of the training process is to initiate a job for developing the fine-tuned model. You can accomplish this task using the OpenAI CLI or one of SDKs, demonstrated below.