



Hugging Face – “The AI community for building the future”

Hugging Face (🤗) – an open-source data science and machine learning platform, providing an environment to host, train, and collaborate on AI models. It furnishes the necessary infrastructure to support your journey from initial code conception to deploying AI within live applications or services. In addition to these capabilities, the platform allows access to models created by others, facilitates dataset exploration and usage, and offers the opportunity to test demo projects. Hugging Face aims to engage a wide array of individuals in shaping the future of artificially intelligent tools because only open source collaboration can bring real results.
A significant feature of Hugging Face is the ability to create own AI models, hosted directly on the platform. This functionality enables you to enrich model information, upload essential files, and maintain version control. You retain the authority to decide whether your models remain public or private, determining the timing and conditions for their launch.
The platform also fosters discussions directly on the model page, facilitating collaboration and managing pull requests, where contributors suggest code updates. Once your model is ready for utilization, Hugging Face provides seamless access—you can run the model directly from the platform, send requests, and integrate outputs into your applications.
For those seeking to avoid building from scratch, Hugging Face’s extensive model library boasts over 200,000 models offering capabilities such as:
► Natural Language Processing (NLP), encompassing tasks like translation, summarization, and text generation—core features akin to OpenAI’s GPT-3 used in ChatGPT.
► Audio-related functions that include automatic speech recognition, voice activity detection, and text-to-speech.
► Computer vision tasks facilitating real-world visual comprehension, covering depth estimation, image classification, and image-to-image tasks, critical for applications like autonomous vehicles.
► Multimodal models adept at processing diverse data types (text, images, audio) and generating multiple output formats.
Hugging Face’s Transformer library simplifies interaction with these models. Users can connect, assign tasks, and obtain outputs without the need for complex setups. The platform further enables model downloads, custom training with personal data, and swift Space creation. This seamless integration allows easy access to diverse models for various tasks, connection with custom code, and prompt delivery of results.
Main Features
Hugging Face – cornerstone of modern NLP through its wide set of core components and features that cater to a wide range of language processing needs.
Transformers Library
The Transformers library embodies a comprehensive suite of cutting-edge machine-learning models exclusively crafted for Natural Language Processing (NLP). It encompasses a vast array of pre-trained models finely tuned for tasks like text classification, language generation, translation, and summarization, among other functions.
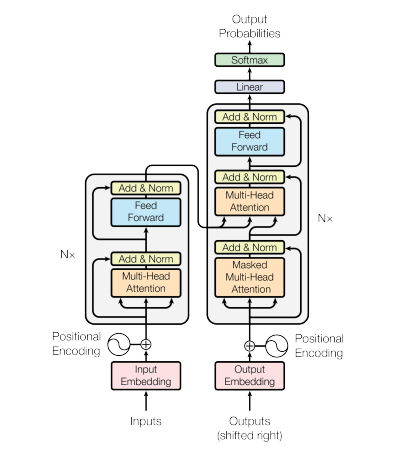
Transformer architecture
At the core of Hugging Face lies the pipeline() method, abstracting common NLP tasks into an accessible API. These pipelines offer a straightforward approach for users to apply intricate models to real-world challenges. These models are highly accessible and adaptable, marking a revolutionary leap for developers and researchers, significantly contributing to the accessibility of sophisticated NLP models.
Its significance lies in simplifying the intricate processes involved in training and deploying NLP models, enabling practitioners to incorporate advanced NLP functionalities with minimal coding requirements. The library’s prowess lies in its capacity to abstract complexities, eliminating the need to delve into the intricate algorithms powering these models.
The Transformers library streamlines the implementation of NLP models in various fundamental ways:

Model Hub
The Model Hub serves as the front-facing platform for the community, offering access to thousands of models and datasets. It stands as an innovative feature enabling users to share and explore models contributed by the community, fostering a collaborative environment for the advancement of Natural Language Processing (NLP) development.
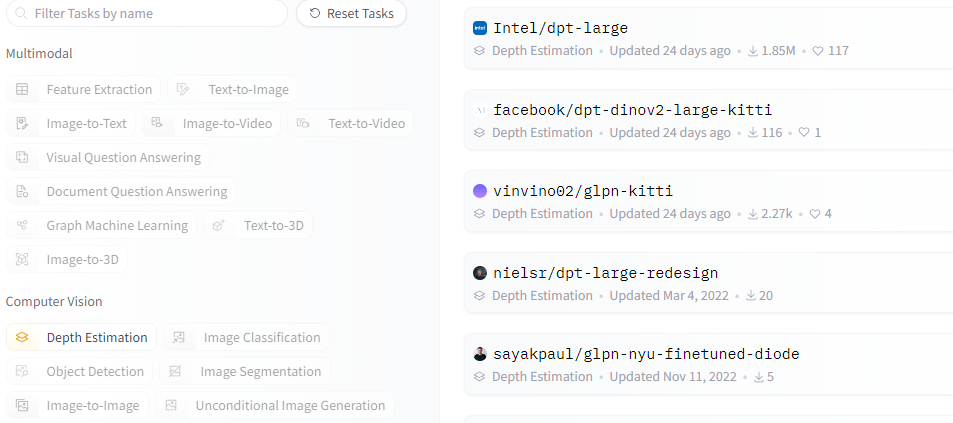
The left-sidebar provides various filters catering to the primary task to be executed.
Hugging Face streamlines the process of contributing to the Model Hub through its user-friendly tools, assisting users in uploading their models seamlessly. Once contributed, these models become accessible to the entire community, either directly through the hub or via integration with the Hugging Face Transformers library.
This simplicity in access and contribution cultivates a vibrant ecosystem where cutting-edge models undergo continuous refinement and expansion. This collaborative framework serves as a fertile ground for the evolution and enhancement of Natural Language Processing technologies.
Tokenizers
Hugging Face offers an array of user-friendly tokenizers meticulously optimized for their Transformers library. These tokenizers are instrumental in seamlessly preprocessing text. For a more detailed exploration of Tokenization, you can refer to a separate article.
Tokenizers play a crucial role in NLP, serving as the core components responsible for converting text into a machine-readable format essential for comprehending various languages and text structures.
Their primary function involves breaking down text into tokens—fundamental units such as words, subwords, or characters—preparing data for machine learning models. These tokens serve as the fundamental elements enabling models to comprehend and generate human language.
Additionally, tokenizers aid in transforming tokens into vector representations, facilitating model input, and managing padding and truncation to maintain consistent sequence lengths.
Datasets
Datasets constitute another vital component of Hugging Face, encompassing the Datasets library, an extensive reservoir of NLP datasets important for supporting the training and evaluation of ML models.
This library stands as an indispensable resource for developers within the domain, presenting a diverse compilation of datasets applicable for training, testing, and benchmarking a wide spectrum of NLP models across numerous tasks.
Its primary advantage lies in its intuitive and user-friendly interface. While users can explore and peruse all datasets available in the Hugging Face Hub, the tailored dataset library facilitates effortless downloading of any dataset for seamless integration into your code.
The repository incorporates datasets catering to commonplace tasks like text classification, translation, and question-answering, along with more specialized datasets addressing unique challenges within the field.
How to use Hugging Face models in own project
Requirement
The initial query revolves around intention for using an AI model. Hugging Face boasts a comprehensive array of models catering to nearly every need. Therefore, it’s crucial to define precisely what you aim to achieve. Once you have a clear confirmation on your objective, you can proceed to the next step.
Installation
Hugging Face provides support for over 20 libraries, including widely used frameworks such as TensorFlow, PyTorch, and FastAI. To integrate Hugging Face into your workflow, you can utilize the ‘pip’ command to install these libraries.
Once the PyTorch is installed, install the transformer library using the below command:

Model Choosing
Navigate to the Hugging Face models section, where you’ll find an extensive collection of pre-trained models designed for diverse tasks. Suppose your objective is language translation. In this section, select the ‘translation’ tag to filter and display models specifically trained for translation tasks. On the right side, available models for your task will be presented. Proceed by clicking on each model to evaluate if it aligns with your specific requirements.
Model Ispection
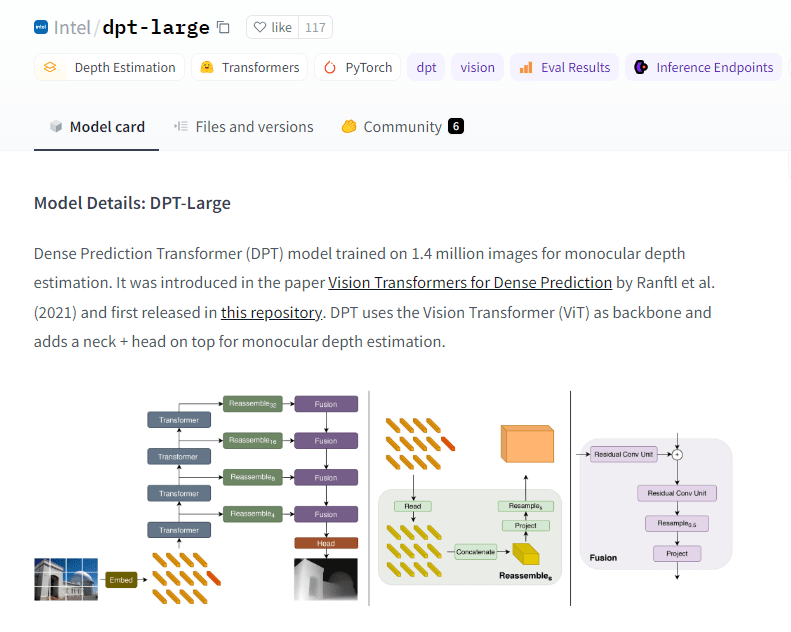
Select any model to access detailed information. Additionally, you have the option to train or fine-tune this model according to your preferences. On the right side, note the crucial box labeled “</>. Scrolling down the page reveals further comprehensive details about the model. This includes insights into its training methodology, applications, the datasets employed for training, and other pertinent information.
Check how it was already used
It can be that individuals and companies have already implemented model, you want to use, for their distinct purposes. Exploring how others have utilized it within their specific contexts is invaluable. This exploration allows you to grasp the model’s potential and assess its utility. Click on the boxes to examine the code and any additional information available, offering insights into practical applications and usage scenarios.
Learn about Pipeline
Hugging Face offers a convenient pipeline that grants access to nearly every model, eliminating the necessity to individually download each model. Look for the box labeled “</> Use in Transformer.” This box contains code enabling the utilization of this model within the Transformer pipeline. If you intend to incorporate it into your project using the pipeline function, another code snippet will be provided. Additionally, you can refer to the documentation for guidance on implementing the model.
When working with pipelines, the convenience lies in not having to implement each step individually. You can simply select a pipeline that suits your specific use case and create a machine translator with just a few lines of code, as illustrated below:
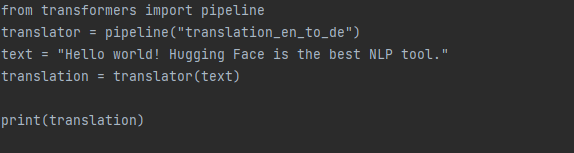
Load a pre-trained model
Now that we already know what model to use, let’s use it in Python. Using these AutoModel classes will automatically infer the model architecture from the model name.
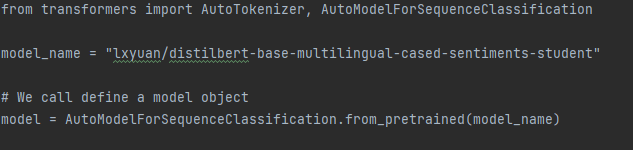
Run the model
Create a pipeline object that includes the selected model, tokenizer, and the designated task. Initializing the classifier object with the task allows the pipeline class to populate it with default values, although this approach is not recommended for production scenarios.

Are there alternatives?
In today’s dynamic landscape of Natural Language Processing (NLP), numerous platforms vie for attention as viable alternatives to Hugging Face. These alternatives offer diverse features, tools, and functionalities, catering to various needs within the NLP domain. Understanding the range of options available is crucial for individuals and organizations seeking tailored solutions beyond the offerings of the Hugging Face platform.
Huggingface’s collaboration with other services
Hugging Face has collaborated with various services and platforms, expanding its reach and enhancing its offerings in the field of Natural Language Processing (NLP). Some notable collaborations include:
♦ Google Cloud: Hugging Face partnered with Google Cloud to provide access to its Transformer models via the Google Cloud AI Platform. This collaboration enables developers to deploy and leverage Hugging Face’s models directly within Google Cloud infrastructure.
♦ Microsoft Azure: Collaboration with Microsoft Azure Machine Learning to integrate its models and tools into the Azure ecosystem. This collaboration allows Azure users to utilize Hugging Face’s extensive library of models for NLP tasks within the Azure environment.
♦ IBM Cloud: Hugging Face has integrated its models into the IBM Cloud Pak for Data, allowing users of the IBM Cloud to access and utilize Hugging Face’s models for various NLP applications.
♦ Amazon Web Services (AWS): While there might not be a direct collaboration announced, developers can use Hugging Face’s models on AWS infrastructure through deployment methods available on AWS services.
♦ Kaggle and Colab: Hugging Face’s tools, models, and datasets are often used and shared within the Kaggle community and Google Colab notebooks. Users leverage Hugging Face’s offerings to perform NLP tasks, share code, and collaborate on projects.
These collaborations and integrations across various cloud platforms and services aim to make Hugging Face’s models, libraries, and tools more accessible to developers, data scientists, and researchers within their preferred environments, enhancing the capabilities of NLP applications and fostering innovation in the field.
Hugging Face simplifies the integration of NLP tasks into systems, handling the complexity involved. By leveraging their APIs, we can effortlessly develop NLP solutions. The platform offers an open-source repository, providing an entry point for anyone to dive into NLP problem-solving. Additionally, their website hosts insightful tutorials that serve as excellent guides to navigate their library.





